Industry research consistently shows that a majority of enterprise AI initiatives fail to meet expectations or stall before reaching meaningful scale. But enterprise AI projects don't fail because of the technology. They fail because of how they're scoped. Organizations often launch with overly ambitious deployments before the basics have been validated, and when things go wrong across a broad system, it's difficult to know where to start fixing them.
At StackAI, we consistently see that organizations that succeed start with a narrow scope, learn from real usage, and scale what's working. This article covers three things: why that approach works, what it looks like in practice through two real case studies, and a framework you can use to run your own rollout.
Why Staged Rollouts Work
Here are four key reasons why staged rollouts consistently outperform big-bang implementations:
Easier to Debug
When an agent is scoped to a specific task, failures are easier to identify and fix. A narrow system has fewer variables, which means you can isolate what's going wrong and address it directly. The wider the scope, the harder that becomes.
Build Trust Incrementally
A failed pilot on a low-stakes workflow is a contained, recoverable setback. A failed rollout on something high-visibility can set back AI adoption across the organization for a long time. Starting small gives you room to learn and adjust before the stakes are higher.
Validate the Economics Before Scaling
It's easier to measure ROI on a single, well-defined workflow than across a complex system. Proving value at small scale gives you a clearer and more defensible basis for deciding where and how much to expand.
Build Team Competency Along the Way
If this is your team's first AI deployment, starting with lower-risk workflows gives everyone time to get familiar with the technology, tooling, and integration patterns before taking on more critical processes. That experience compounds as the system grows.
Patterns We See Repeatedly in Successful Deployments
The principles reflect how successful enterprise AI rollouts actually unfold. Across industries, we consistently see the same progression: narrow scope first, specialization before expansion, and integration only after performance stabilizes.
Two recurring patterns illustrate how this plays out in practice.
Pattern 1: Specialize First, Then Integrate
Example: Internal IT Support
Challenge: Support agents wasted IT time on repetitive questions. First-response times had degraded to 24 hours.
The initial instinct is often to build a universal support agent covering every single topic. But in reality, teams that succeed do the opposite.
The Staged Approach:
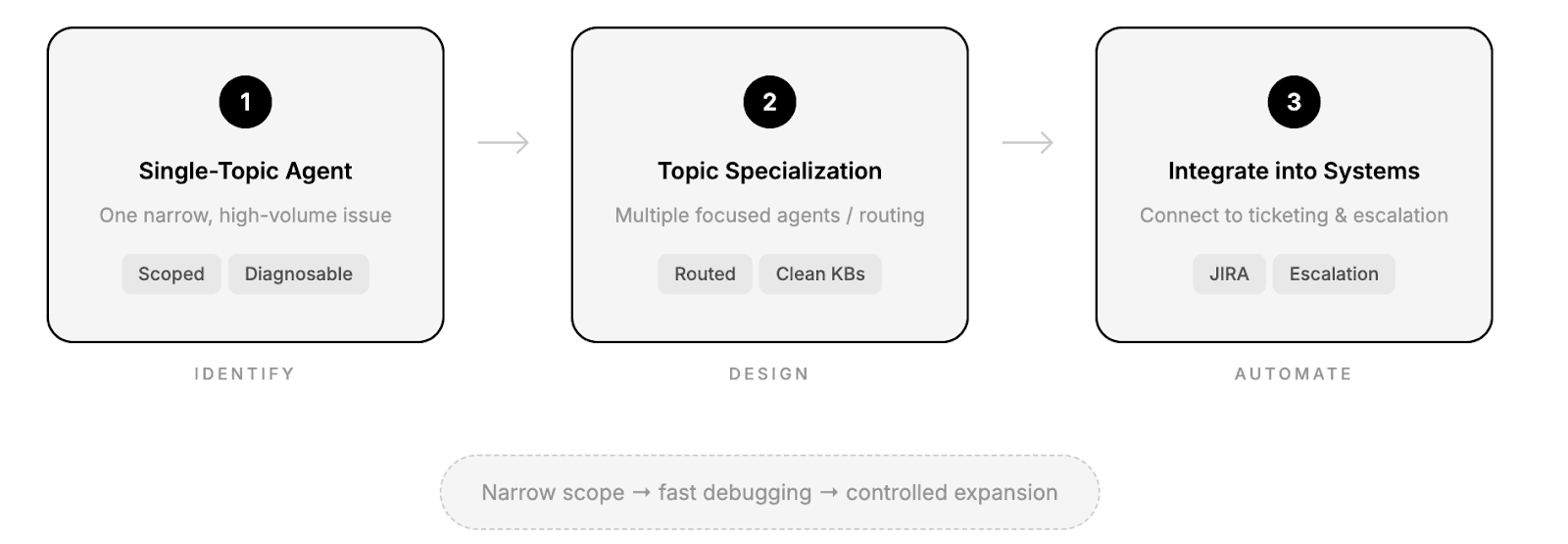
Phase 1 – Single-Topic Agent
Instead of building a general IT bot, they start with a tightly scoped agent focused on one high-volume issue (e.g., VPN or remote access).
The knowledge base is intentionally small and vetted.
Accuracy at this stage is rarely perfect, often 60–70%. But that’s not the goal. The goal is clarity. With narrow scope, every incorrect answer points directly to a document gap, retrieval issue, or prompt flaw. Debugging becomes concrete and fast.
Phase 2 – Topic Specialization
Rather than stretching one agent across topics, successful teams create multiple focused agents or routing layers. Security questions route to a security-focused agent. HR-related IT questions route elsewhere.
Multiple specialized agents consistently outperform a single general-purpose one. Each knowledge base remains clean. Each failure remains diagnosable. Accuracy improves because complexity stays contained.
Phase 3 – Integrate Into Existing Systems
Only after performance stabilizes do teams connect the agents to ticketing systems like JIRA. At this stage, the agent can create tickets, route requests, and immediately escalate to humans when confidence is low.
Pattern 2: Automate the Assembly, Not the Judgment
Example: Financial Services Use Case
Challenge: Analysts spent over 20 hours weekly on manual data aggregation for investment memos: pulling financial metrics from multiple sources, formatting tables, cross-referencing historical data. The memos were primarily descriptive data assembly, yet the process consumed time that should have gone toward qualitative analysis and investment judgment.
This case illustrates a principle we emphasize with every financial services client: automate the assembly, not the judgment.
The Staged Approach:
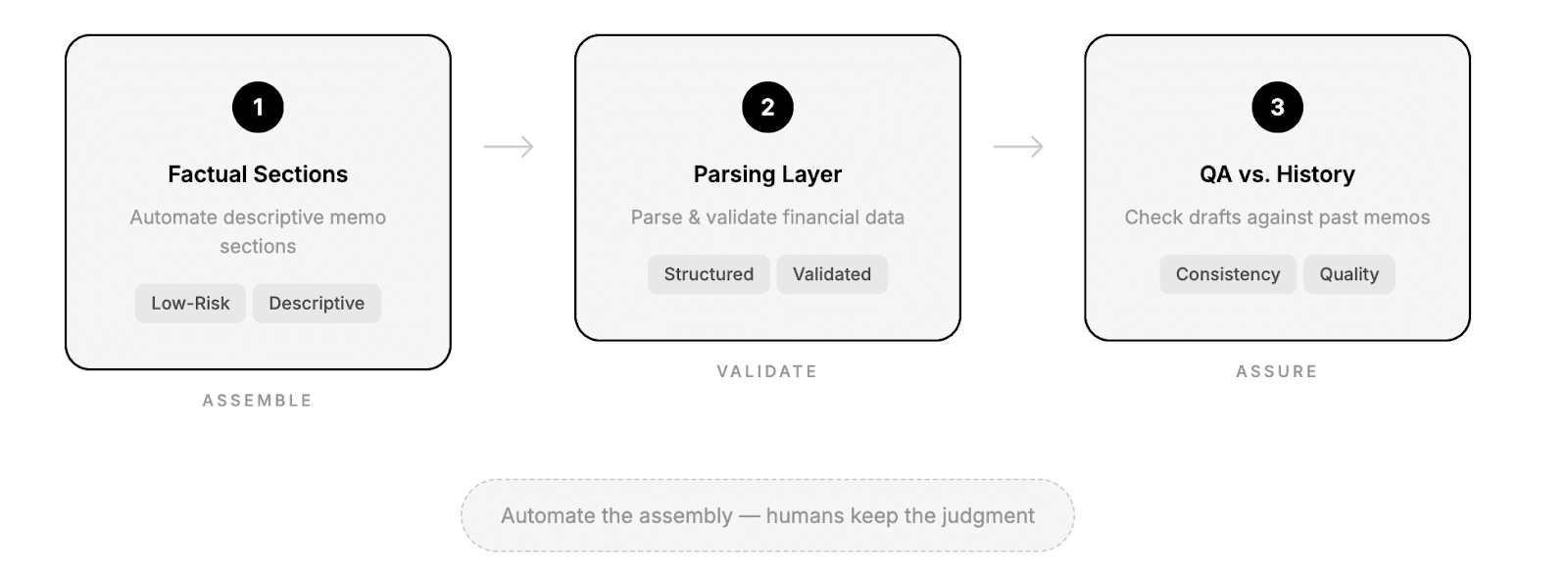
Phase 1 — Automate the factual sections
The agent handled low-risk, descriptive sections: market size, competitor landscape, regulatory environment. Analysts kept full control over interpretation and analysis.
Phase 2 — Financial Data Parsing Layer
Financial documents are inconsistent: 10-Ks, transcripts, pitch decks all vary in format.
Successful teams implement a parsing layer that extracts structured data from unstructured sources and applies validation rules to catch discrepancies. This reduces manual effort and prevents basic data errors.
Phase 3 — Quality Assurance Against Historical Memos
Rather than generating memos end-to-end, mature deployments add a QA layer. Drafts are compared against previously approved memos to flag missing sections, structural inconsistencies, or deviations from standard methodology. The system improves consistency, not just speed.
The impact? Substantial time savings, fewer errors, and more analyst time spent on actual investment reasoning.
A Practical Implementation Framework
You understand why staged rollouts work. You've seen what they look like in practice. Now here's how to execute your own:
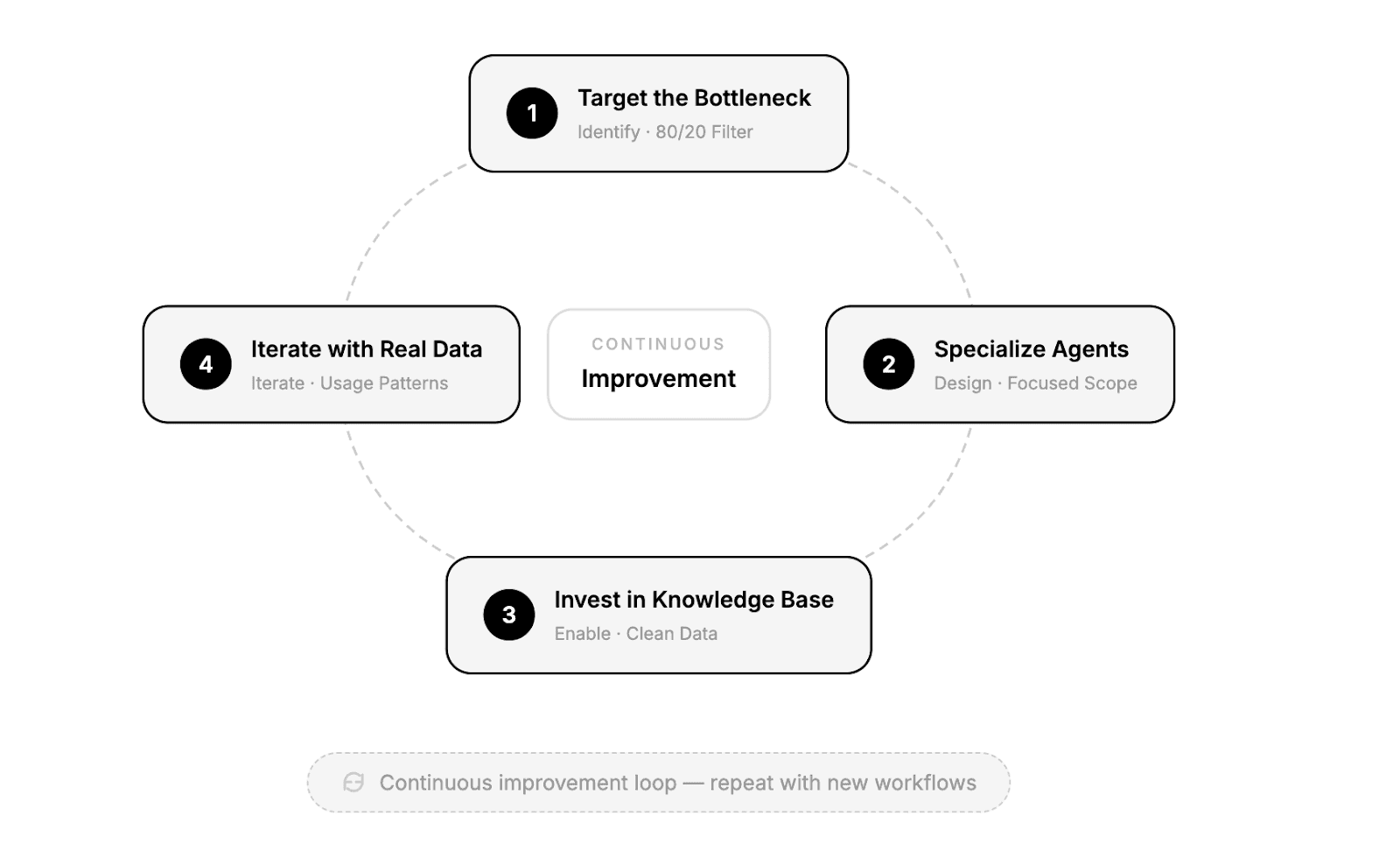
Target the Bottleneck (The 80/20 Filter). Look for tasks that are high-frequency and low-judgment. These are the workflows where your team spends the most time on work that doesn't require expertise. Don't start with edge cases or anything that requires signific.ant human discretion. The goal is to identify the 20% of friction causing 80% of pain.
Specialize agents rather than scaling complexity. Focused agents remain debuggable, their knowledge bases stay clean, and failures remain diagnosable.
Invest disproportionately in knowledge base quality. The most common source of AI failures in enterprise settings isn’t the model, but the data. Clean, well-structured documentation is the single highest-leverage investment you can make.
Use real usage data, not assumptions, to guide iteration. Every expansion decision (new topics, new integrations, new workflows) should be driven by actual user behavior and failure patterns, not roadmap ambitions.
The Bottom Line
Embracing iterative learning in AI development isn’t just a risk-mitigation strategy, it’s the fastest path to production. The pattern holds consistently: teams that start small and iterate deliberately reach enterprise-scale deployment in months, getting the fastest time to value, while the teams that start big are often still debugging their pilot a year later. The complexity of AI rewards patience, precision, and a willingness to let real-world results dictate the next step.
For a personalized rollout framework, get a demo with our team of AI experts.

Marta Llopis
AI Strategist at StackAI

