Retrieval-Augmented Generation (RAG) is a strong way to reduce hallucinations and keep answers anchored in the right context.
🔗 Learn More: To learn more about building RAG workflows with LLMs, check out this post.
In RAG, we have a retrieval layer and a generative layer. But in practice, the real deal behind a reliable RAG system isn’t just these layers alone themselves. It's also the prompts that tie everything together.
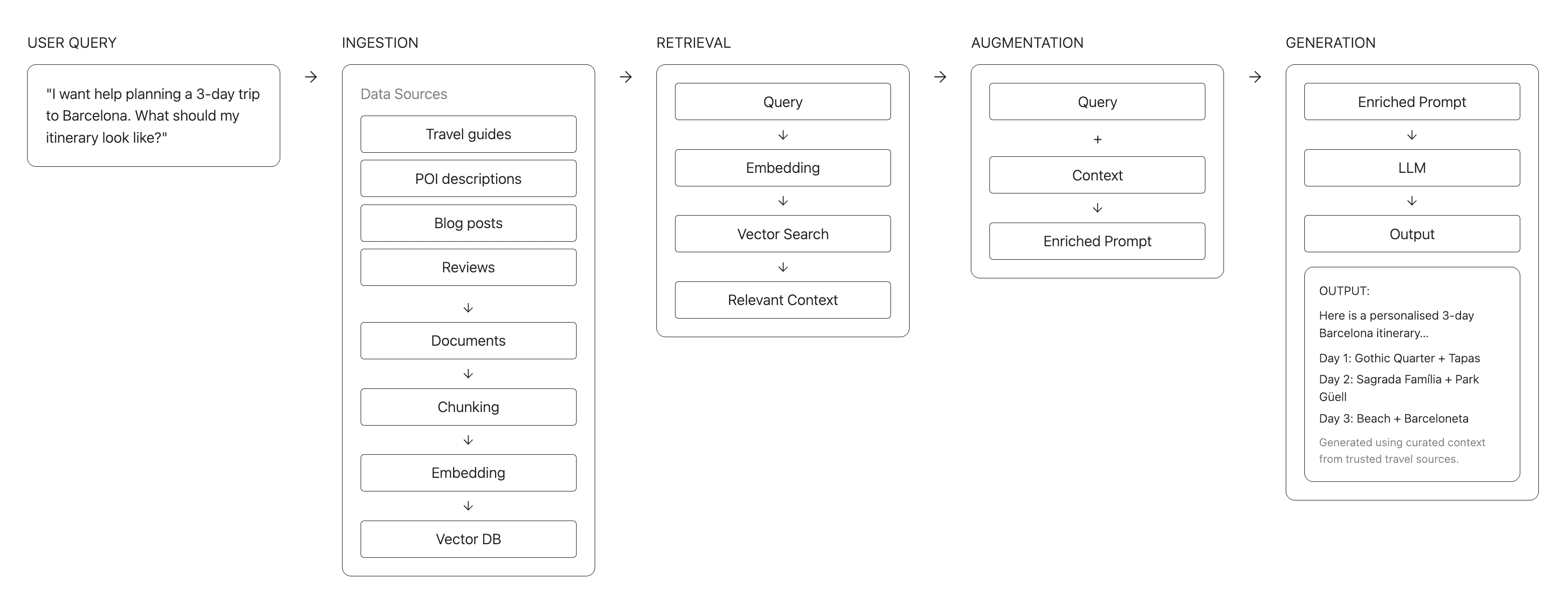
Many issues in a RAG pipeline come from prompts that are unclear, overloaded, or inconsistent. Weak retrieval makes things messy, but weak prompts make things unusable.
So while you're trying to fix hallucinations with more embeddings, more chunking, or extra model call, the real issue is often in how the system and user prompts are written, combined, or positioned in the workflow.
This article breaks down the prompt patterns that keep RAG stable, grounded, and easy to scale.
We’ll look at the differences between system and user prompts, how to structure both, how to apply n-shot and reasoning prompts, explore promoting best practices and look into a real-world use case.
If you’re building RAG systems, these techniques will help you design prompts that stay clear and grounded even with complex data and fast-changing questions.
Why Prompt Engineering is the Base of Effective RAG Workflows
RAG pipelines are often characterized by two "neat" steps: retrieve the right information, then let the model produce an answer. But prompting also plays an important role in this process. It affects how the model interprets the retrieved content, how it reasons through ambiguity, how it handles missing context, and how much control you retain over the final output.
In practice, two RAG systems with the same data, same embeddings, and same model can behave completely differently purely due to prompt structure.
A well-designed system prompt can help making sure answers are grounded in retrieved context. A clear user prompt can guide the model toward the exact output format a product needs. Together, they form the control surface for the entire workflow.
This is why prompt engineering is not a cosmetic add-on. It defines the model’s role, its limits, its level of strictness, and the way it treats retrieved content.
When prompts are vague, overloaded, or poorly separated, the model drifts, hallucinations rise, and retrieval becomes less effective. When prompts are precise and structured, the model becomes predictable, stable, and easier to scale.
Good RAG depends on good retrieval and generation. Great RAG depends on good prompting.
🔗 Learn More: To learn about the difference between fine-tuning and RAG, check out this post.
The Dual Prompt Structure: System vs. User Prompts
Every RAG pipeline uses two main prompt layers: the system prompt and the user prompt.
System Prompt: The Persistent Instruction Layer
The system prompt sets the base rules the model must follow across every single request. This is the prompt that operates in the background, which guides the model’s behavior and keeps it consistent.
It can define:
The model’s role
Tone and communication style
Refusal patterns (“If the answer is not in the context, say you don’t know.”)
Grounding instructions
Formatting rules (lists, JSON, structured outputs)
Domain or industry guidance
Because it never changes, it becomes the anchor of the workflow. This is where you place rules you always want active, no matter what question comes in.
User Prompt: The Dynamic Query Layer
The user prompt is the flexible layer. It holds everything tied to the current request, such as:
The user’s question
Task-specific instructions
Examples (when using n-shot prompting at the user level)
Output preferences relevant to this moment
This layer should stay lightweight and clear. When it becomes overloaded, the model struggles to prioritize instructions.

Why Separation Matters
Many problems in RAG workflows come from mixing these two layers. When instructions are scattered across both, the model may ignore the wrong rule, prioritize short-term instructions over long-term ones, and may lose behavior consistency between queries.
Clear separation prevents this.
It keeps the workflow organized and ensures the model follows the right rules at the right time.
A clean split between system and user prompts is the first step toward a RAG pipeline that behaves consistently, scales smoothly, and stays simple to maintain as your documents and use cases grow.
The table below breaks down how each prompt functions and what choices teams need to make when designing both layers.
Aspect | System Prompt | User Prompt |
Purpose | Sets the model’s identity, rules, limits, and behavior | Carries the current question or task |
Stability | Stays the same across all calls | Changes with every query |
Content | Tone, safety rules, formatting, grounding instructions, domain guidance | User’s question, task details, short task-specific instructions |
Best For | Maintaining consistency and preventing drift | Directing the model toward the current goal |
Risks When Misused | Too many instructions → rigid behavior or long context overhead | Overloaded prompts → confusion, weaker grounding |
Placement of RAG Context | Sometimes used here when context must shape behavior (e.g., long-term rules or domain knowledge) | Often used here for question-specific retrieved chunks |
Examples |
|
|
Impact on RAG Quality | Controls grounding, refusal patterns, and precision | Controls accuracy, clarity, and output structure for each individual request |
Practical Takeaway
Put rules and non-negotiable instructions in the system prompt.
Put the question and moment-specific instructions in the user prompt.
Keep both clean and tightly scoped.
Most RAG instability comes from mixing these two layers or repeating instructions across them.
Prompt Engineering Techniques for RAG
Effective RAG systems rely on more than basic prompt templates. Once retrieval is working and the pipeline is stable, the next step is shaping prompts that guide the model toward consistent reasoning, grounded answers, and clear output formats. Let’s look at some techniques:
N-Shot Prompting in RAG
N-shot prompting involves giving the model a set of examples showing how a task should be handled. These can be questions: answer pairs, structured outputs, or walkthroughs of reasoning. The goal is simple: show the model what “good” looks like.
Examples can live in either prompt layer:
System prompt: When the examples represent long-term patterns (e.g., how a company writes product summaries or handles support cases)
User prompt: When examples relate only to this one task or dataset
Both: In complex workflows where global rules and task-specific patterns need to coexist
There are a couple of things one should watch for:
Longer examples increase token usage
Retrieval chunks can push examples out of the context window if not planned
Too many examples can reduce clarity rather than provide guidance
Used well, n-shot prompting gives the model clear signals and reduces guesswork, especially in tasks that require structured outputs. Below are examples of this kind of prompt.
This example would shape the default structure for every output, no matter what question comes in. But n-shot prompting can also occur in the user prompt:
This example guides the model for this specific conversation or dataset, but does not become a global rule.
Chain-of-Thought and Other Reasoning Prompts
RAG often involves information spread across several retrieved chunks. Chain-of-thought encourages the model to reason step-by-step, combine evidence, and avoid jumping to unsupported conclusions.
This is how you can apply it:
System prompt: “Think through the evidence step-by-step before forming your answer.”
User prompt: “Show your reasoning before giving the final response.”
Hidden CoT: Ask the model to reason silently and output only the final answer (useful when you want clarity without exposing the chain).
Agentic RAG workflows can add review loops, critiques, or verification steps. The prompts for each stage should guide the model to:
Check its own answer
Verify grounding
Identify gaps
Compare retrieved content from different steps
These reasoning instructions reduce the risk of unsupported conclusions and encourage more careful evidence use.
System Prompt Example:
User Prompt Example:
Chain-of-Thought Example:
Multi-Stage Agentic RAG: Reasoning Steps
Multi-stage workflows add review, critique, and verification steps. Each step gets its own prompt.
Stage 1: Draft Answer Example
Stage 2: Self-Check and Critique Example
Stage 3: Final Answer Synthesis Example
This sequence reduces hallucination risk and improves grounding.
Optimizing Prompts for RAG: Best Practices
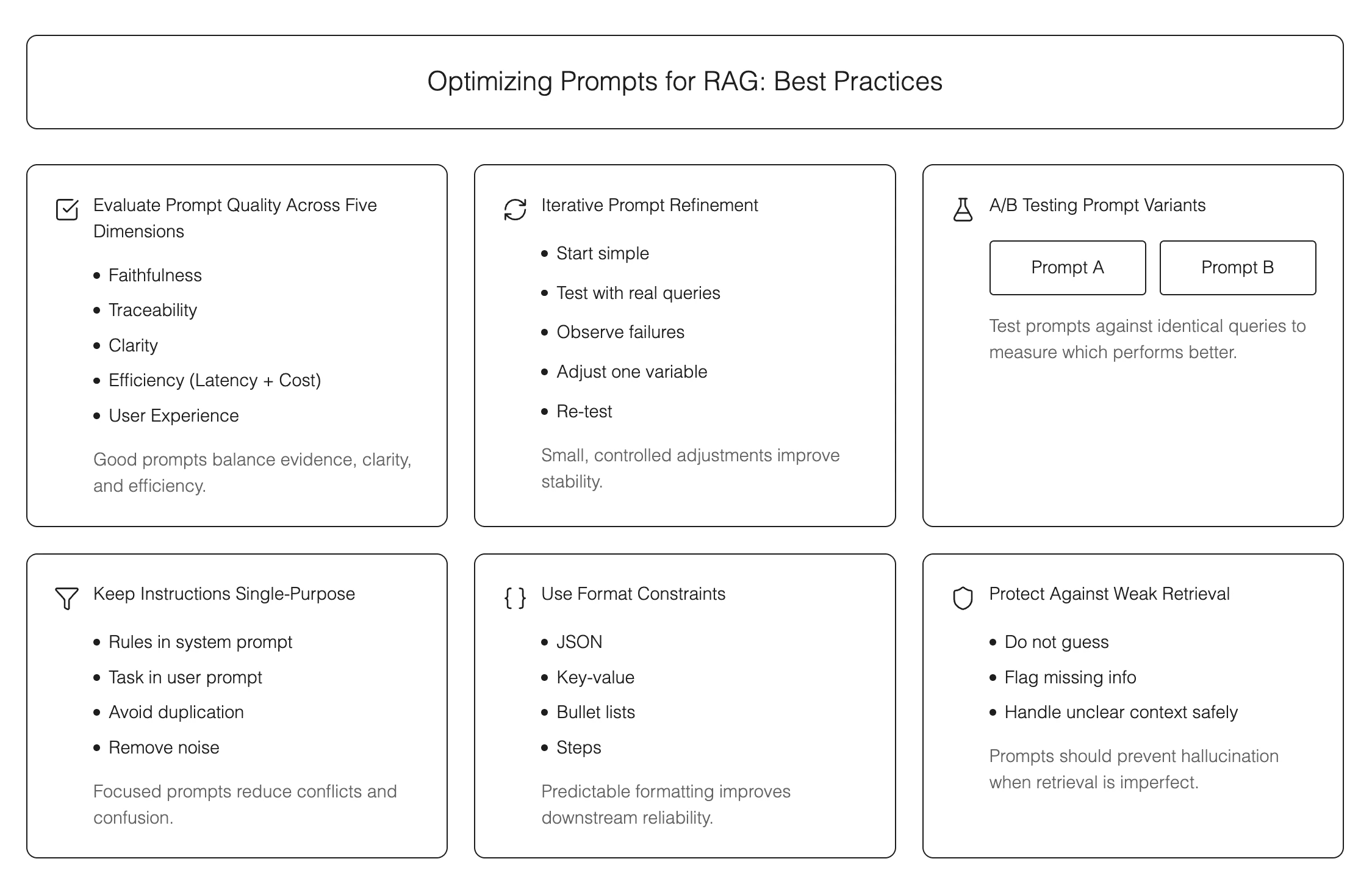
As mentioned in the previous sections, strong retrieval alone doesn’t guarantee reliable answers. The quality of a RAG system often depends on small, careful choices in how prompts are written, structured, and tested. The following principles help keep outputs grounded, stable, and easy to maintain as the system grows.
Evaluate Prompt Quality Across Five Dimensions
A good RAG prompt should meet the following criteria:
Faithfulness: The model uses only the retrieved context and avoids inventing details.
Traceability: The output can be tied back to specific pieces of retrieved evidence.
Clarity: The instructions are simple, direct, and free from competing rules.
Latency + Cost: Examples, reasoning steps, and long descriptions increase token usage. Prompts should be as short as possible while still guiding the model effectively.
User Experience: Outputs must be readable, structured, and predictable, especially when integrated into tools, dashboards, or end-user apps.
Use Iterative Prompt Refinement
Prompt tuning is rarely solved on the first attempt. A reliable approach is to:
Start with a simple prompt.
Run real queries (high-volume and edge cases).
Identify failures.
Adjust one variable at a time.
Re-test with the same dataset.
This controlled iteration avoids chaos and helps you understand exactly which changes lead to improvement.
Run A/B Tests for New Prompt Variants
Another technique is to test two prompts in parallel rather than guessing:
Prompt A: current version
Prompt B: adjusted version
Same set of questions and documents
Compare for grounding, clarity, and format consistency
Keep Instructions Single-Purpose
Crowded prompts confuse the model. Good patterns:
Place rules in the system prompt
Keep the user prompt focused on the task
Avoid repeating instructions in multiple places
Remove anything that doesn’t directly influence output
This reduces noise and keeps the reasoning path clear.
Add Format Constraints When Needed
For production systems, predictable output is essential. Prompts can set:
JSON structures
Key-value formats
Bullet points
Step-by-step layouts
Format constraints help the model stay consistent and reduce post-processing errors.
Protect the Model From Weak Retrieval
Even with strong embeddings, retrieval sometimes returns content that is irrelevant or incomplete. Build protective measures into prompts:
“If the context is unclear or incomplete, respond with X…”
“If the answer cannot be found, do not guess.”
“Highlight missing information if needed.”
This helps prevent the model from compensating with invented details.
Applying These Techniques in StackAI: A Practical Use Case
To show how prompt engineering shapes real outcomes inside StackAI, let’s walk through a practical scenario: building an AI Staff Training Assistant.
The goal: help employees learn internal processes, product knowledge, and workplace rules, using your existing documents as the source of truth.
This example uses a mix of system prompts, user prompts, retrieval blocks, n-shot examples, reasoning prompts, and guardrails, all combined inside StackAI.
Use Case: Staff Training AI Assistant
Imagine a company that wants new employees to learn:
how internal tools work
how sales/ops/HR handle common tasks
product knowledge
compliance rules
customer support scripts
The company has PDFs, Notion pages, training guides, slide decks, and meeting notes but no simple way for staff to query all of it.
Designing the System Prompt in StackAI
The system prompt sets the permanent behavior for the assistant. In StackAI, you drop this into the instruction field in the model mode. For our use case, we are going to design the following prompt:
For the user prompt, we keep the question short and clear. Long user prompts don’t guide the model, better they usually add noise. So a direct question like "who approves my expense reports?” gives the model exactly what it needs: a focused query it can match against the retrieved context without distractions.
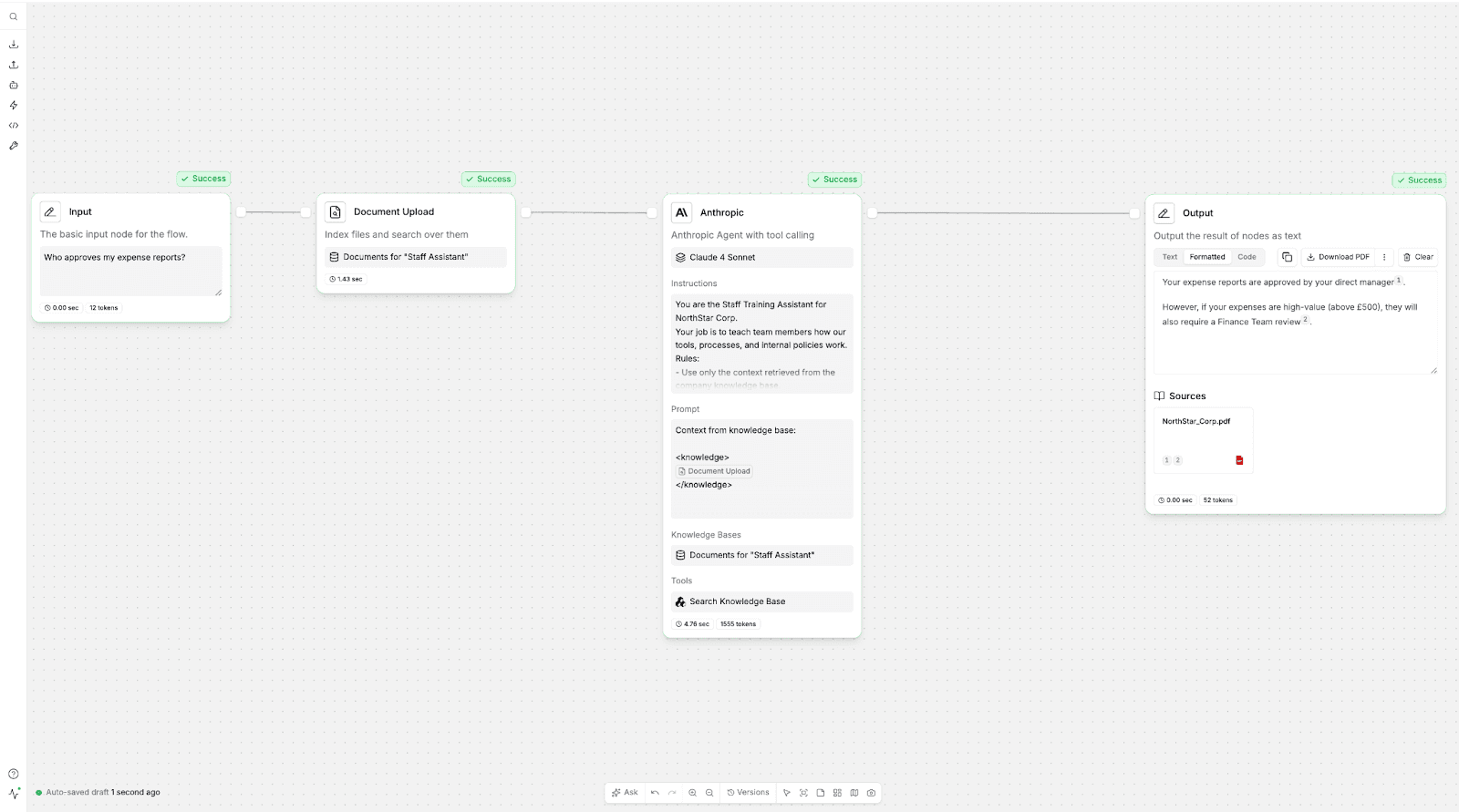
The output demonstrates how a well-designed RAG setup in StackAI behaves when the prompts, retrieval, and knowledge base all work together as intended. Given our prompt, we get responses such as:
This is fully based on the training document we added to the knowledge base. Nothing is invented. No guessing.
The model correctly picked the most relevant part of the retrieved context. This aligns with the chain-of-thought guidance we gave it in the system prompt (“review each piece of context, combine details carefully”).
The answer is short, clear, and task-focused. This is because firstly, the user prompt was concise, and secondly, we gave guidance on the type of output in the system prompt and providing examples
Also, the answer is formatted in a simple, readable way. The system prompt sets the tone and clarity rules, and the model follows them:
First sentence = main rule
Second sentence = exception / detail
No unnecessary detail
This shows that the style examples in the system prompt influence the structure.
Finally, source documents are shown. StackAI automatically links back to the exact pages used in the response. This improves trust and makes the assistant suitable for internal training and compliance workflows. You can see that the answer pulled from NorthStar_Corp.pdf, pages 1 and 2 — a great example of traceability.
🔗 Learn More: To learn about even more advanced RAG techniques, see this post.
Final Thoughts
RAG systems only reach their full potential when the prompts are clear, structured, and consistent. Retrieval gives the model the right information, but the prompts have an effect on how that information is used, how the model reasons, and how stable the answers stay across different queries.
Separating system and user prompts, adding n-shot examples when needed, guiding reasoning with chain-of-thought, and taking into account prompting best practices, you give the model a well-defined path to follow. These patterns keep answers grounded and reduce the risk of drift or unsupported claims.
StackAI makes this practical. You can shape prompts, test variants, run evaluation flows, and refine the structure until your RAG workflow behaves reliably with real data. With the right prompt design, your assistant becomes easier to manage, easier to scale, and far more predictable.
Strong prompts turn RAG from a basic search-plus-generation setup into a clear, controlled system that your team can trust. Want to see RAG in action on StackAI? Book a demo today.

Ana Rojo-Echeburúa
Growth at StackAI

